









3 min read
Understanding the Elements of a Modern Data Solution
Written by: Timextender - January 13, 2021
There are many terms that can be confusing as one considers how to organize their data and how to plan for using different types of data structures and models. Let’s take a look at some of the more common terms used in the data management field and what they mean to a business or organization.
1. To start, what are the differences between data warehouses, data lakes, and data marts?-
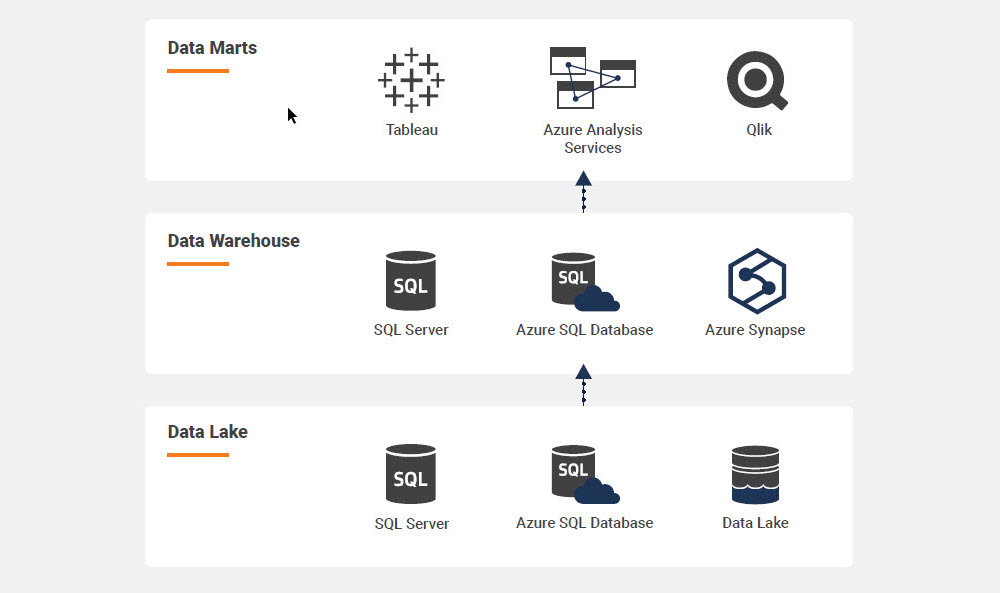
- Data Warehouses (DWs or DWHs), also known as enterprise data warehouses (EDWs), are repositories for storing data for the use of business intelligence (BI), reporting, and advanced analytics. In some cases, data warehouses are preferred by business professionals and analysts to quickly report on and visualize their organized data.
- Data Lakes are repositories that allow all data (structured and unstructured) to be stored even though an organization might not have an existing plan on how to use the data. In some cases, data scientists prefer data lakes so they can see all the raw data and create their own ETL pipelines for nuanced experimentation.
- Data Marts are subsets of an enterprise-wide data warehouse that store data and are used by a specific business unit, department, or team such as sales or finance.
2. What are the advantages and disadvantages of each?
-
- Data Warehouses make it really fast for reading and aggregating data, as the data is well-organized, or modeled, in a way that make aggregation, advanced analytics, and reporting straight-forward. DWs model data for an enterprise by leveraging data lakes and databases to create data pipelines for BI. Developers and architects may use dimensional modeling to integrate data based on how business users create BI reports, analyses, and advanced analytics. The data warehouse can be invaluable to stakeholders and business decision makers to understand their business. However, creating and maintaining a data warehouse can a be a difficult and demanding task when done the traditional way (“coded completely by hand”), rather than with automation software like TimeXtender.
- Data Lakes make it really fast to write data of any kind to a single location, and are often used to integrate siloed data sources as a building block for an ETL pipeline, advanced analytics and BI. Data Lakes provide an economical, performant, and scalable solution for integrating data into a data warehouse but do not necessarily provide information on how data is related or make business insights easy to find. The disadvantage is that the data often requires significant wrangling, cleansing, or “munging” before it becomes really valuable, much like precious stones that require cutting and polishing.
- Data Marts require data to be processed, cleaned, and validated to provide value. A data mart is a solid solution that allows a particular business unit to store only pertinent data for their relevant business users. Data marts don’t tell the whole story of a business, but are specific in their scope and use cases, for refined KPIs and benchmarks, as well as dashboards and visualizations.
3. Do these three data storage technologies interrelate at all?
Absolutely! One common architecture TimeXtender recommends is leveraging the best of all three. The data warehouse models the data to support BI and advanced analytics or machine learning. The Data Lake becomes the storage unit for the raw data in the data warehouse. And data marts are created from the data warehouse by organizing the data into business units and leveraging the data for reporting for the specific business units by using BI dashboards.
4. Please explain how TimeXtender technology supports these technologies? Specifically, what type of Microsoft-related technologies is TimeXtender compatible with for each of these data-storage capabilities?
TimeXtender automates, accelerates, and simplifies the process of building and maintaining an enterprise data warehouse. Furthermore, TimeXtender is the fastest way to access, model, and document an enterprise-data solution, backed by the Microsoft stack (Azure Data Lake and SQL DBs, SQL Server, Analysis Services, Active Directory).
Since on-premise, hybrid, or purely cloud-based (Azure) solutions are natively supported by the platform, there is an element of future-proofing the data warehouse solution as the business grows and changes over time.
TimeXtender is comprised of three layers to achieve the following:
-
- Azure Data Lake Storage Gen2 storage is a great way to store raw data, and TimeXtender’s Operational Data Exchange (ODX) layer makes it very easy to connect to 200+ enterprise data sources. Staging raw data in ADLS Gen2 is secure, economical, performant, and scalable.
- Although TimeXtender is a low-code/no-code solution, the Modern Data Warehouse (MDW) automatically writes T-SQL for the developer using SQL Server as the engine. The data warehouse holds the business logic, allowing for version control, multiple environments, and always up-to-date documentation. This works by capturing the only the meta-data of your project, but allowing you to be flexible by choosing your data storage. To explain, a solution may build an on-prem data warehouse to easily point to an Azure SQL DB (i.e. Managed Instance, Serverless, etc.), with just a few clicks once the resource is created. The Azure Marketplace holds pre-configured TimeXtender solutions, using Azure Services paired with VMs, so one can begin building in just a few minutes.
- To create data marts, or semantic models, TimeXtender’s Semantic Layer (SL) leverages SQL Server Analysis Services Tabular Models behind the scenes to create the segmented, cleansed, and curated business units. The benefit of creating these data marts in TimeXtender is easy to recognize when thinking about how easy it is to create these always up-to-date, fully documented datasets so one can simply connect to endpoints such as Power BI to begin designing right away.
Hopefully this summary helps provide some clarity to these data terms. You can always visit our “resources” section on our website for more information. This guest post also addresses this subject matter as well.