









10 min read

The Modern Data Stack: A Fragmented Approach
Scroll to the bottom for a summary.
Most companies today are attempting to build their data infrastructure by piecing together highly-complex stacks of disconnected tools and systems. This fragmented approach is often referred to as the "modern data stack." It's essentially just the "legacy data stack," with upgraded tools and a fresh coat of paint, that's been hosted in the cloud.
In its most basic form, a modern data stack will include:
- Cloud-based data storage
- Data ingestion tools
- Data transformation and modeling tools
- Business intelligence and visualization tools
However, the tools in modern data stack can be expanded to cover virtually any data and analytics use case or workflow:
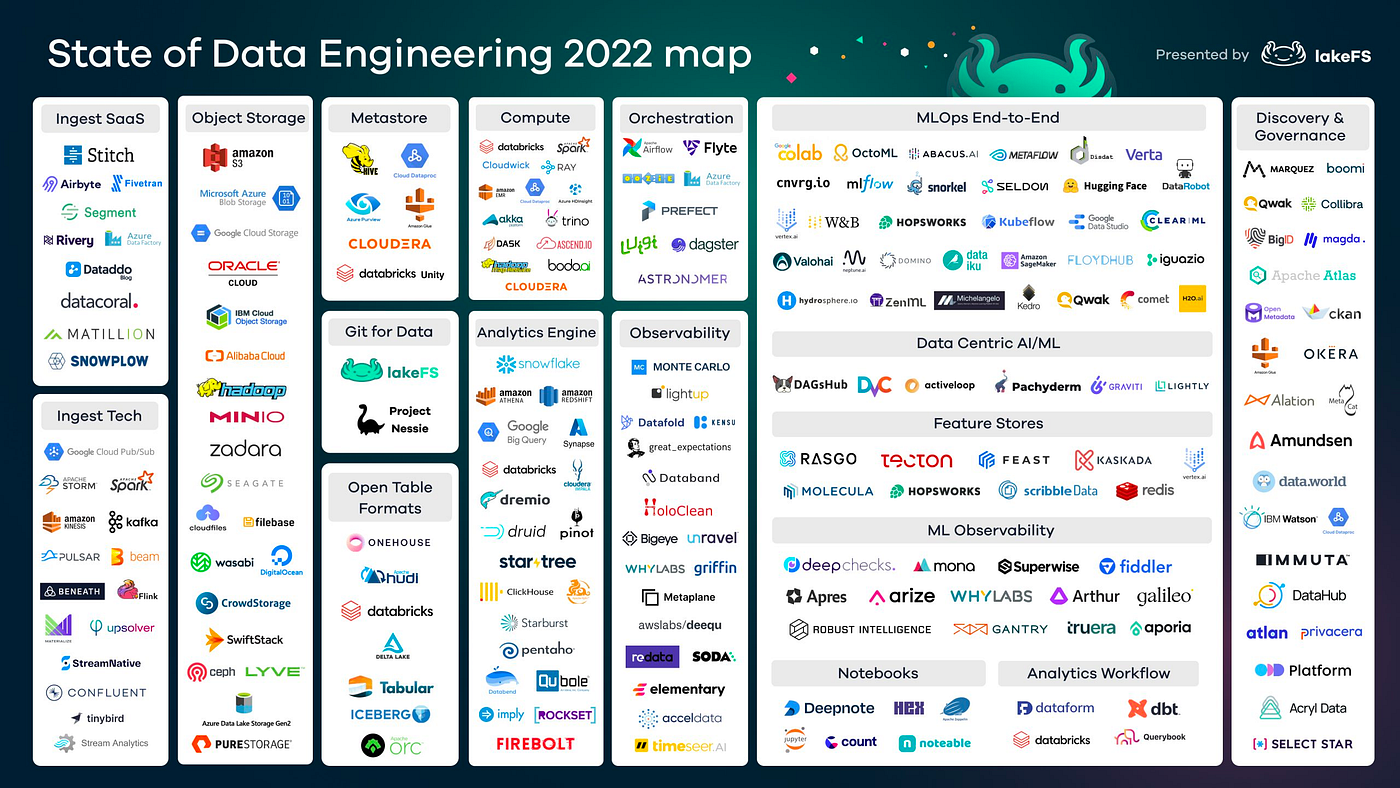
"I joke about this a lot, but honestly I feel terrible for someone buying data technology right now. The fragmentation and overlaps are mind-blowing for even an insider like me to fully grasp."
– Prukalpa Sankar, Co-Founder of Atlan
New Data Stack. Same Old Data Problems.
The modern data stack promises to provide a smarter, faster, and more flexible way to build data solutions by leveraging the latest tools and technologies available on the market.
While the modern data stack is a significant improvement over the traditional method of coding data pipelines by hand with legacy tools, it has also faced criticism for failing to live up to its promises in many ways.
Not only does the modern data stack fail to overcome the challenges of the Data Divide, it creates additional obstacles that must be addressed if you choose this fragmented approach:
-
Tool Sprawl: One of the main criticisms of the modern data stack is the sheer number of tools and technologies available, which can be overwhelming for organizations and make it difficult to choose the right combination of tools to fit their specific needs. Recent research from the Connectivity Benchmark report found that organizations are using 976 individual applications, on average. Yet only 28% of these applications are integrated. Using disconnected tools and technologies across multiple teams can result in data silos, inefficiencies, poor data quality, and security risks due to overlapping functionality and poor integration.
- Procurement and Billing Headaches: With so many tools and technologies to choose from, it can be challenging to navigate the procurement process, which includes negotiating contracts with multiple vendors, managing licenses and subscriptions, and keeping track of multiple billing cycles. This can result in wasted time, budget overruns, and administrative headaches.
- High Cost of Ownership: Implementing and maintaining a highly-complex stack of tools requires a team of specialized experts, which can be very expensive. Additionally, the cost of licensing fees, infrastructure costs, training costs, support and maintenance costs, and other operating expenses can quickly add up, especially if your organization has limited resources or budget constraints.
- Lengthy Setup, Integration, and Maintenance: The modern data stack has yet to fulfill its promise of providing "plug-and-play" modularity. Setting up, integrating, and maintaining a complex stack of tools is still a time-consuming and resource-intensive process. With so many different tools and technologies to manage, it can be difficult for organizations to keep up with updates, troubleshoot issues, and ensure that all components of the stack are working well together. This can lead to delays and increased costs, as well as reduced agility and the inability to respond quickly to changing business needs. Additionally, support is fragmented across multiple vendors, leading to confusion and delays when issues arise.

-
Manual Coding: While many tools in the modern data stack promise low-code, user-friendly interfaces with drag-and-drop functionality, the reality is that manual coding is still often necessary for many tasks such as custom data transformations, integrations, and machine learning. This can add another time-consuming layer of complexity to an already fragmented stack, and requires specialized expertise that can be difficult to find and afford.
- Fragile Data Pipelines: In the modern data stack, traditional data pipelines are not only rigid and specialized but also heavily reliant on manual coding. This reliance on custom coding for each pipeline stage increases the risk of errors and inefficiencies, exacerbating the fragility of the entire data system. Such manual processes impede quick adaptation to changes, making the pipelines less agile and more prone to breakdowns
-
Disjointed User Experience: Due to the highly-fragmented nature of the modern data stack, each tool has its own user interface, workflow, and documentation, making it difficult for users to navigate and learn the entire stack. Users often have to switch between multiple tools and interfaces to complete a single task. This disjointed user experience can be frustrating and time-consuming, leading to reduced productivity and burnout.
- Knowledge Silos: This fragmented approach can also lead to knowledge silos, where different teams or individuals become experts in specific tools or technologies and don't share their knowledge or collaborate effectively with others. This can create a lack of cross-functional understanding and communication, which can result in missed opportunities and suboptimal data solutions. Additionally, if a key team member with specialized knowledge leaves the organization, it can create a knowledge gap that is difficult to fill and may impact the overall effectiveness of your data solution.
-
Staffing Challenges: The highly specialized nature of many of the tools in the modern data stack means that organizations may need to hire or train staff with specific skill sets in order to use them effectively. This can be a challenge in a highly competitive job market, and can further increase the costs associated with building and maintaining a data solution using this fragmented approach.
-
Lack of Consistent Data Modeling: With different tools and systems being used across teams and departments, it can be difficult to ensure that everyone is working with the same data definitions, schema, and semantics (a "single version of truth"). This lack of consistent data modeling can undermine the reliability of your data, make it difficult to perform accurate analysis and reporting, and lead to misinformed decision-making.
-
Lack of Holistic Data Governance: In the modern data stack, control is dispersed across multiple tools, systems, and users. With this fragmented approach, it’s extremely challenging to enforce policies that ensure data is being collected, analyzed, stored, shared, and used in a consistent, secure, and compliant manner.
-
Lack of Observability: As the number of tools and systems grows, it becomes increasingly difficult to document and monitor data as it flows through the various stages of the pipeline. Lacking a unified view of your entire data infrastructure (a "single pane of glass") significantly reduces your ability to catalog available data assets, track data lineage, monitor data quality, ensure data is flowing correctly, and quickly debug any issues that may arise.
-
Increased Security Risks: With data spread across so many tools and systems, it can be difficult to identify where data is stored and who has access to it, which increases the risk of misuse by internal users and unauthorized access by malicious actors. Additionally, if the infrastructure is not regularly maintained, patched, and monitored for anomalies, there is an increased risk of malicious actors exploiting vulnerabilities in the system.
-
Lack of End-to-End Orchestration: With the modern data stack, end-to-end orchestration can be a challenge due to the multiple tools and systems involved, each with its own workflow and interface. This lack of orchestration can result in delays, errors, and inconsistencies throughout the data pipeline, making it difficult to ensure that data is flowing smoothly and efficiently.
-
Limited Deployment Options: One of the biggest limitations of the modern data stack is the lack of support for on-premises or hybrid approaches. Many organizations still prefer to keep some or all of their data infrastructure on-premises or in a hybrid environment due to security or compliance concerns, as well as cost considerations. However, most tools in the modern data stack are designed to be cloud-native, which means they are optimized for use in a cloud environment and do not support on-prem or hybrid setups.
- Vendor Lock-In: Over time, you may become dissatisfied with a particular vendor’s service or support, or they may suddenly raise their prices to an unacceptable level. Many vendors may make it difficult or expensive to migrate data out of their system, which can create significant challenges if your organization decides to switch to a different solution. Vendor lock-in can limit flexibility and innovation and make it difficult for your organization to adapt to changing business needs.
"Having this many tools without a coherent, centralized control plane is lunacy, and a terrible endstate for data practitioners and their stakeholders. It results in an operationally fragile data platform that leaves everyone in a constant state of confusion about what ran, what's supposed to run, and whether things ran in the right order. And yet, this is the reality we are slouching toward in this “unbundled” world."
– Nick Schrock, Founder of Elementl
Unfortunately, most organizations are spending significant amounts of time and money implementing this “modern” data stack, but they aren’t getting any closer to turning their data into actual business value.
These obstacles have caused the modern data stack to fail at delivering on its most basic promise: to help companies build smarter, faster, more flexible data solutions in a timely, cost-effective manner.
This fragmented approach requires expensive tools, complex architectures, extensive knowledge, and a large team to implement, which are out of reach for many organizations.
The true power of data lies in its accessibility, yet the “modern data stack” has too often become a tool of exclusivity. These factors are effectively “gatekeeping” the industry by discouraging newcomers and preventing smaller organizations from reaping the full benefits of their data.
This gatekeeping of the data industry has created an environment where only the companies with the most resources can truly thrive, while smaller organizations and data teams continue to be pushed out and left behind.
We know how slow, painful, and expensive this approach is from years of first-hand experience as IT consultants. We struggled through all these same obstacles when helping our clients build their data infrastructures.

Modern Data Stack: A TANGLED PATCHWORK OF TOOLS
It has become clear that the so-called “modern” data stack has created a broken experience that has failed to help organizations bridge the Data Divide.
Just as Dr. Frankenstein’s monster was an abomination of mismatched parts, the modern data stack has become a tangled patchwork of disparate tools, systems, and hand-coded pipelines that can wreak havoc on your data infrastructure.
But how did we end up with these monstrosities in the first place?
How MODERN DATA stacks Are Born
The answer lies in the rapid evolution of data management tools and the relentless pressure to stay ahead of the curve. As organizations scrambled to adopt new technologies and keep up with competitors, they began adding more and more tools to their stack, with little time to consider the long-term consequences. Like a bunch of mismatched puzzle pieces, these tools are often incompatible, redundant, and poorly integrated — leading to a chaotic, jumbled, expensive mess.
To make things even worse, many organizations also create a tangled web of hand-coded pipelines. It’s easy to get carried away with complexity when building a data pipeline. We add more and more steps, integrate multiple tools, and write custom code to handle specific tasks. Before we know it, we’ve created a sprawling, fragile network of pipelines that is difficult to maintain, troubleshoot, and scale.
The result is the modern data stack. The stack is slow, unreliable, and prone to failure — held together by hastily-written code, ad hoc integrations, workarounds, and patches — requiring significant resources to keep it functioning even at a basic level.
The Looming Data Debt Crisis
This haphazard approach not only slows down your organization but also creates an environment ripe for the accumulation of Data Debt, which is the technical debt that builds up over time as organizations hastily patch together their data stacks, prioritizing immediate needs over sustainable, well-architected solutions.
While organizations may revel in their perceived progress as they expand their data capabilities, they fail to recognize the impending doom that building a modern data stack will bring.
And like any other debt, Data Debt must eventually be repaid — often at a much higher cost than the initial investment. Organizations that continue to ignore the looming threat of Data Debt may find themselves grappling with an unmanageable mess of systems, struggling to make sense of their data, and ultimately falling behind in a competitive marketplace.
The true cost of Data Debt is not just the resources wasted on managing and maintaining these stacks; it’s the missed opportunities for growth and innovation as your organization becomes increasingly bogged down by its unwieldy data infrastructure.
What Are You Optimizing For?
"What are you optimizing for?" is a crucial question that organizations must ask themselves when considering which data and analytics approach to take.
The stakes are extremely high, as the wrong approach can result in wasted time and resources, missed opportunities for innovation and growth, and being left on the wrong side of the Data Divide.
So, are you optimizing for...
-
New technology trends?
-
A fragmented data stack?
-
Highly-customized code?
-
DevOps frameworks?
-
Ingrained habits?
-
Organizational momentum?
-
Gaining marketable skills?
You can’t optimize for everything, all at once.
If you choose to optimize for fragmentation or customizability, you will be forced to make big sacrifices in speed, agility, and efficiency.
.png?width=553&height=311&name=Copy%20of%20Copy%20of%20Copy%20of%20Gray%20Fearless%20Blog%20Banner%20(1).png)
At the end of the day, it’s not the organizations with the most over-engineered data stacks or the most superhuman coding abilities that will succeed.
While having an optimized data stack and skilled coders are certainly beneficial, it is important to remember that the ultimate goal of data and analytics is simply to drive business value.
“The Modern Data Stack ended up solving mostly engineering challenges related to cost and performance, generating more problems when it comes to how the data is used to solve business problems.
The primary objective of leveraging data was and will be to enrich the business experience and returns, so that’s where our focus should be.”
– Diogo Silva Santos, Senior Data Leader
A Holistic Approach to Bridging the Data Divide
Given these challenges, organizations of all sizes are now seeking a new solution that can unify the data stack and provide a more holistic approach to data integration that’s optimized for agility.
Such a solution would be...
-
Unified: It would provide all the features needed to easily ingest, prepare, and deliver clean, reliable data, without a large team or a complex stack of expensive tools.
-
Metadata-Driven: It would utilize metadata to orchestrate workflows, automatically document projects, ensure holistic data governance, provide a comprehensive data catalog for easy discovery and access to data assets, and help users understand their data and its lineage.
-
Automated: It would automate tedious, manual tasks, while still providing powerful customization options and developer tools, when needed.
-
Seamless: It would seamlessly integrate with, accelerate, and leverage your existing data infrastructure, without vendor lock-in.
-
Agile: It would empower organizations of all sizes to level the playing field, while also providing the agility and flexibility they need to grow and adapt to a rapidly-changing technology landscape.
By breaking down the barriers of the modern data stack and eliminating the exclusivity that plagues the industry, this new solution could finally unlock the full potential of data for everyone.
We realized we couldn't just sit around and hope for someone else to create such a solution.
So, we decided to create it ourselves.
Meet TimeXtender, the Holistic Solution for Data Integration
The so-called "modern" data stack traces its origins back to outdated architectures designed for legacy systems. We believe it's time to reimagine what's possible through simplicity and automation.
Meet TimeXtender, the holistic solution for data integration.
TimeXtender provides all the features you need to build a future-proof data infrastructure capable of ingesting, transforming, modeling, and delivering clean, reliable data in the fastest, most efficient way possible - all within a single, low-code user interface.
You can't optimize for everything all at once. That's why we take a holistic approach to data integration that optimizes for agility, not fragmentation. By using metadata to unify each layer of the data stack and automate manual processes, TimeXtender empowers you to build data solutions 10x faster, while reducing your costs by 70%-80%.
TimeXtender is not the right tool for those who want to spend their time writing code and maintaining a complex stack of disconnected tools and systems.
However, TimeXtender is the right tool for those who simply want to get shit done.

From modern data stack to Holistic Solution
Say goodbye to a pieced-together "stack" of disconnected tools and systems.
Say hello to a holistic solution for data integration that's optimized for agility.
Data teams at top-performing organizations such as Komatsu, Colliers, and the Puerto Rican Government are already taking this new approach to data integration using TimeXtender.
Summary
- The “Modern Data Stack” is a fragmented approach to data infrastructure, involving various tools and systems.
- This approach has numerous challenges, such as tool sprawl, high costs, lengthy setup, manual coding, disjointed user experience, staffing challenges, knowledge silos, lack of consistent data modeling, holistic data governance, observability, security, end-to-end orchestration, and limited deployment options.
- The modern data stack often fails to deliver on its promises, resulting in wasted resources and missed opportunities for innovation and growth.
- Organizations must ask themselves what they are optimizing for when choosing a data and analytics approach; customization or agility?
- A holistic solution would be unified, metadata-driven, automated, seamless, and agile.
- TimeXtender is the holistic solution for data integration, offering a unified and low-code interface to build data solutions faster and more efficiently.