









6 min read

As organizations grow and evolve, they naturally begin adopting new tools and systems to keep up with changing demands and technology. This eventually leads to a situation where different departments and teams within the organization are using separate tools for each of their individual needs and use cases.
In fact, recent research from the Connectivity Benchmark report found that organizations are using 976 individual applications, on average. Yet only 28% of these applications are integrated.
This fragmented approach has become commonplace in most organizations, creating a Frankenstein-like monster of disconnected tools that are often redundant, expensive, incompatible, and difficult to manage.
In any organization, there is no place where this is truer than in the data team.
If you’re piecing together a complex stack of disconnected applications, tools, and systems to create your “modern data stack,” you’re probably already spending more time and resources setting up, integrating, and maintaining these tools than you should be.
Click here to jump to the summary.
MODERN DATA STACKS Are Scarier Than You Might Think
Just as Dr. Frankenstein’s monster was an abomination of mismatched parts, a modern data stack is created from a tangled mess of tools and technologies. Setting up, integrating, and maintaining a modern data stack often turns into a cautionary tale of pure terror.
If you're working with a stack of data tools, it's time to face the real horror of the situation:
-
Tool Sprawl: One of the main criticisms of the modern data stack is the sheer number of tools and technologies available, which can be overwhelming for organizations and make it difficult to choose the right combination of tools to fit their specific needs. It’s like being lost in a dark, mysterious, enchanted forest with no clear path forward, as the tangled web of tools becomes more and more confusing.
-
Procurement and Billing Headaches: With so many tools and technologies to choose from, it can be a complete nightmare to navigate the procurement process, which includes negotiating contracts with multiple vendors, managing licenses and subscriptions, and keeping track of multiple billing cycles. This can result in wasted time, budget overruns, and administrative headaches that feel like they may never end.
-
High Cost of Ownership: Like a caged monster that requires constant feeding and attention, the modern data stack requires a team of specialized experts to keep it running smoothly. In addition to the costs associated with hiring these experts, the licensing fees, infrastructure costs, training costs, support and maintenance costs, and other operating expenses can add up quickly. This can be especially terrifying for organizations with limited resources or budget constraints, as they may find themselves in a never-ending cycle of increasing costs and decreasing returns.
-
Lengthy Setup, Integration, and Maintenance: With so many different tools and technologies to manage, it can start to feel like being trapped in a haunted mansion, where each door leads to another room filled with new obstacles and horrors. Setting up, integrating, and maintaining a complex stack of tools is still a time-consuming and resource-intensive process. It can be difficult for organizations to keep up with updates, troubleshoot issues, and ensure that all components of the stack are working well together. To make things even worse, support is fragmented across multiple vendors, leading to confusion and delays when issues arise.

-
Manual Coding: While many tools in the modern data tack promise low-code, user-friendly interfaces with drag-and-drop functionality, the reality is that manual coding is still often necessary for many tasks such as custom data transformations, integrations, and machine learning. Just like a sorcerer conjuring ancient magic, data engineers must possess specialized skills to perform manual coding, and only a select few possess the knowledge to bring forth the desired outcome. This specialized expertise can be difficult to find and afford for most organizations.
-
Disjointed User Experience: Due to the highly fragmented nature of the modern data stack, each tool has its own user interface, workflow, and documentation, making it difficult for users to navigate and learn the entire stack. Users must navigate this maze of tools, switching between different interfaces and workflows, like trying to escape a haunted labyrinth. This disjointed user experience can be frustrating and time-consuming, leading to reduced productivity and burnout.
- Knowledge Silos: It's crucial for every member of your team to come together and share their expertise to fight back and tame the data stack beast. Unfortunately, a fragmented approach can lead to knowledge silos, where different teams or individuals become experts in specific tools or technologies and don't share their knowledge or collaborate effectively with others. This can create a lack of cross-functional understanding and communication, which can result in missed opportunities and suboptimal data solutions. Additionally, if a key team member with specialized knowledge leaves the organization, it can create a knowledge gap that is difficult to fill and may impact the overall effectiveness of your data solution.
-
Staffing Challenges: The highly specialized nature of many of the tools in the modern data stack means that organizations may need to hire or train staff with specific skill sets to use them effectively. This can be a challenge in a highly competitive job market, like trying to find a brave hero to conquer a ferocious monster, and it can further increase the costs associated with building and maintaining a data solution using this fragmented approach.
-
Lack of Consistent Data Modeling: With different tools and systems being used across teams and departments, it can be difficult to ensure that everyone is working with the same data definitions, schema, and semantics (a "single version of truth"). It’s like trying to solve a mystery in a horror story, but the clues you find are inaccurate and contradictory. This lack of consistent data modeling can undermine the reliability of your data, making it difficult to perform proper analysis and reporting.
-
Lack of Holistic Data Governance: The lack of holistic data governance in a fragmented data stack is like casting a spell that unleashes chaos upon your organization. When control over data is dispersed across multiple tools, systems, and users, it creates an atmosphere of confusion and disarray. With this fragmented approach, it becomes extremely challenging to enforce policies that ensure data is being collected, analyzed, stored, shared, and used in a consistent, secure, and compliant manner.
-
Lack of Observability: As the number of tools and systems grows, it becomes increasingly difficult to document and monitor data as it flows through the various stages of the pipeline. Lacking a unified view of your entire data infrastructure (a "single pane of glass") significantly reduces your ability to catalog available data assets, track data lineage, monitor data quality, ensure data is flowing correctly, and quickly debug any issues that may arise. It’s hearing something go bump in the night, but you can't see what's causing the noise.
-
Increased Security Risks: With data spread across so many tools and systems, it can be difficult to identify where data is stored and who has access to it, which increases the risk of misuse by internal users and unauthorized access by malicious actors. Like monsters lurking in the shadows waiting for the right moment to attack, if the infrastructure is not regularly maintained, patched, and monitored for anomalies, there is an increased risk of malicious actors exploiting vulnerabilities in the system.
-
Lack of End-to-End Orchestration: If you’ve ever watched a horror movie where a group of people fail to work together to fight back against a monster, you know the importance of coordination. With the modern data stack, end-to-end orchestration can be a challenge due to the multiple tools and systems involved, each with its own workflow and interface. This lack of orchestration can result in delays, errors, and inconsistencies throughout the data pipeline, making it difficult to ensure that data is flowing smoothly and efficiently.
-
Limited Deployment Options: Limited deployment options in the modern data stack are like being cursed by a spell that restricts your movements. While some organizations prefer to keep their data infrastructure on-premises or in a hybrid environment, many tools in the modern data stack are designed to be cloud-native. This means they are optimized for use in a cloud environment and do not support on-prem or hybrid setups. The curse of this limitation can make it difficult for organizations to choose the deployment option that works best for their unique situation, leaving them trapped with limited options.
-
Vendor Lock-In: You may initially be satisfied with a vendor's service or support, but over time, they may reveal their true colors, raise their prices to an unacceptable level, and become a total nightmare to work with. Many vendors may make it difficult or expensive to migrate data out of their system and escape their clutches. Vendor lock-in can limit flexibility and innovation and make it difficult for your organization to adapt to changing business needs, leaving you feeling like you’ve been trapped in a dungeon with no hope of escaping.
To avoid these frightening outcomes, it's time to move away from modern data stacks and embrace a holistic solution for data integration.
Meet TimeXtender, the Holistic Solution for Data Integration
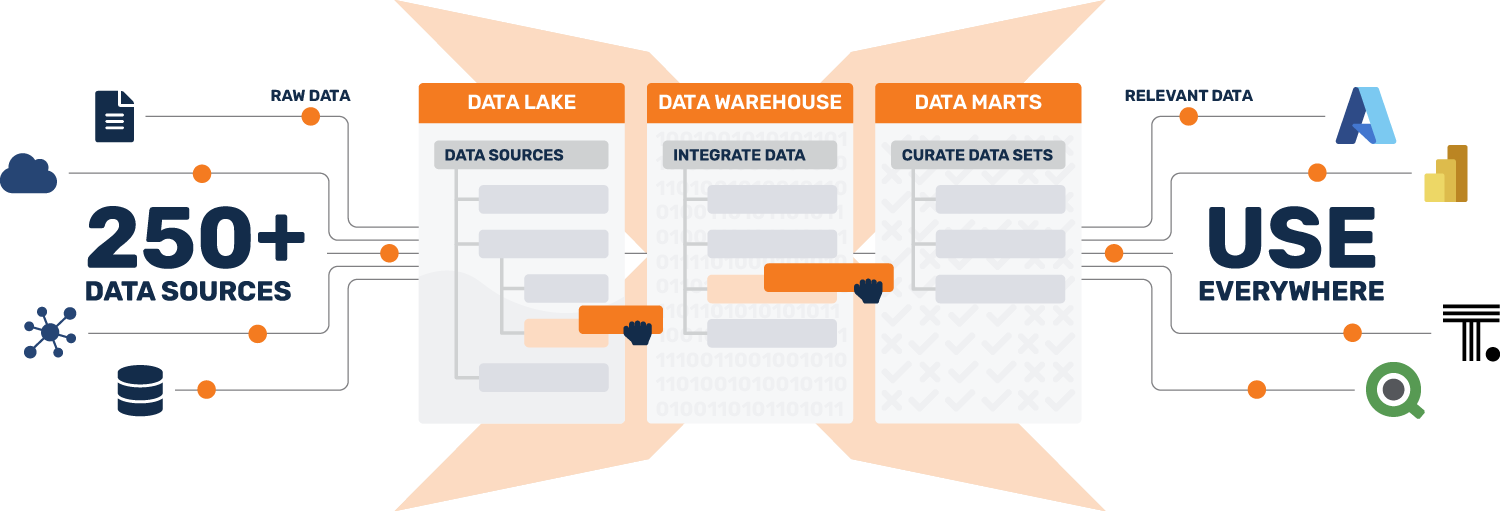
TimeXtender provides all the features you need to build a future-proof data infrastructure capable of ingesting, transforming, modeling, and delivering clean, reliable data in the fastest, most efficient way possible - all within a single, low-code user interface.
You can't optimize for everything all at once. That's why we take a holistic approach to data integration that optimizes for agility, not fragmentation. By unifying each layer of the data stack and automating manual processes, TimeXtender empowers you to build data solutions 10x faster, while reducing your costs by 70%-80%.
TimeXtender is not the right tool for those who want to spend their time writing code and maintaining a complex stack of disconnected tools and systems.
However, TimeXtender is the right tool for those who simply want to get shit done.

From modern data stack to Holistic Solution
Say goodbye to a pieced-together stack of disconnected tools and systems.
Say hello to a holistic solution for data integration that's optimized for agility.
Data teams at top-performing organizations such as Komatsu, Colliers, and the Puerto Rican Government are already taking this new approach to data integration using TimeXtender.
Summary
- Organizations often use numerous disconnected tools and systems, leading to a stack of data tools
- Modern data stacks are inefficient, expensive, and difficult to manage
Issues associated with modern data stacks include:
- Tool sprawl
- Procurement and billing headaches
- High cost of ownership
- Lengthy setup, integration, and maintenance
- Manual coding
- Disjointed user experience
- Knowledge silos
- Staffing challenges
- Lack of consistent data modeling
- Lack of holistic data governance
- Lack of observability
- Increased security risks
- Lack of end-to-end orchestration
- Limited deployment options
- Vendor lock-in
TimeXtender offers a holistic solution for data integration:
- Unified data stack with low-code user interface
- Faster data solution building, reducing costs by 70%-80%
- Optimized for agility, not fragmentation
- Moving from a stack of tools to a holistic solution improves efficiency and reduces costs in data integration.