









3 min read
You’ve probably heard that data is the new oil. To take that analogy farther, data – like oil - needs to be extracted, processed and refined to be useful. And just as oil can be refined into different types of fuel, data can be prepared for different uses when it comes to analytics and artificial intelligence. A data architecture is defined by how a company chooses to prepare data for these different uses.
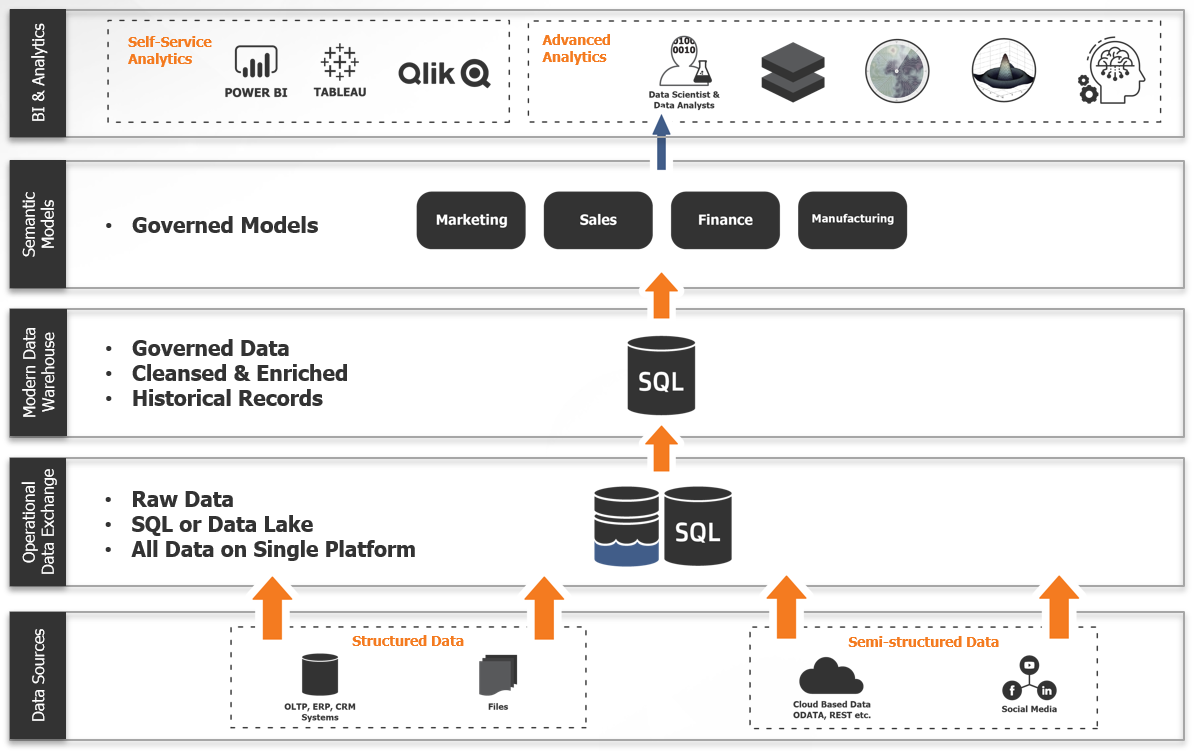
Layer 1: Operational Data Exchange
For instance, data scientists typically start explorations with raw data – meaning data that has not been transformed or altered. Data scientists will perform various types of analysis on raw data to look for anomalies and patterns, and eventually perform machine learning. But it is not practical to perform the required analysis on data that is still in a transactional database because of the performance impact on applications. Plus, there is additional data that may come from outside your organization that require extraction via an API to ensure security of the database and application. The first layer in a data architecture allows consolidation of raw data from multiple sources in a single place for analysis by power users like data scientists. This one stop shop for all enterprise data is commonly in the form of a data lake as it can contain both structured, semi-structured (think social data), and unstructured data (think photos and videos).

Layer 2: Modern Data Warehouse
But raw data isn’t the best choice for data analysts or business analysts. These users need data that has been cleansed, enriched and rationalized – in a modern data warehouse. For instance, in raw data, you may find more than one version of the same data (and they may not match!). So which one should be used? The rules for this are typically written as code (usually SQL code) by a data engineer who knows the data and make determinations to create what is often called “golden records.” This “single source of truth” is updated on a regular basis to ensure the latest data is available for analysis. Slowly changing dimensions and historical data can be maintained in the modern data warehouse when data from your source systems changes or is deleted. In a layered data architecture, the data warehouse would be sourced from the operational data exchange – but placed in a SQL-based database with semi-structured data transformed into structured data for analysis. This movement of data from non-relational to relational allows for stricter schema enforcement enabling faster query times and easier exploration by self-service users.
Layer 3: Semantic Models
In many organizations, there is an increased effort to publish data for non-technical business users – also known as self-service analytics. In these environments, just pointing these users at the data warehouse will be overwhelming – there will be too many choices and too much data for the users to know what to use. The solution is to build semantic models (or data marts) from the data warehouse which provide line of business or function-specific views of what is available in the data warehouse. These models can be targeted at specific parts of the business and only include data that would be relevant for specific areas of analysis. This layer of the data architecture allows data engineers and analysts to provide data that is ready for analysis while allowing business users to determine the analysis they want to do. The semantic models provide “guard rails” to business users so they can explore data safely and efficiently.
Where do I put all this data?
If you put this layered architecture together, you do have two potentially large datasets – probably a data lake and a modern data warehouse. Finding a new data source can grow your datasets in an instant and many organizations find that building and maintaining the data infrastructure to support these large datasets is a bit overwhelming as it requires experts with several skill sets. As a result, a growing percentage of organizations are putting these datasets in the cloud. Cloud services like Microsoft Azure provide robust and scalable data platforms that automatically handle large additions of data without the need to acquire more hardware.

Why implement a layered data architecture?
You may have noticed that this approach creates additional copies of data – with different levels of structure and cleansing. When storage was expensive, this approach may not have been an option. But with storage costs relatively low and cloud options even less expensive, the layered approach makes sense for several reasons.
- The operational data exchange offers a single, consistent and managed source of all internally and externally sourced core business information. It can be made available to advanced users (like data scientists) who need access to raw data. This now acts as a single source for all business data.
- The modern data warehouse provides business users (like business analysts or data analysts) with access to data that is cleansed, enriched, rationalized and ready for analytics. This database is typically highly structured – allowing for speedy queries.
- By providing a set of semantic models based on the modern data warehouse, casual users from lines of business to discover data without being overwhelmed by a complete data warehouse that includes large sets of data that isn’t relevant to their needs. Because the models are generated – you can support multiple tools for visualization and analysis.
- If you use a meta-data driven approach to building these layers, you get data lineage and impact analysis for every data element. And from the meta-data, you should also be able to generate complete documentation regarding your analytics data in support of regulatory requirements.
With data provided to the business in various degrees of governance, analysts and decision-makers have immediate access to all corporate data for any purpose or use case, enabling individuals throughout the organization with the ability to make faster, data-driven decisions.
TimeXtender can help organizations build a modern data estate using this layered data architecture. Learn more about our data management platform for analytics and AI.
