









4 min read

Guiding Principles for Data Warehouse Migrations
A guest blog post from Kevin Petrie, VP of Research at Eckerson Group
So, you’re standing on mountains of data and peering into the Azure cloud. What next?
Many large and mid-sized enterprises that rely on Microsoft SQL Server data warehouses now seek to migrate to the Azure cloud. They see the benefits of layering SQL data warehouse structures onto cloud object storage in the Azure Synapse Analytics platform. They want to use elastic cloud infrastructure to improve scalability, agility, and efficiency. But to achieve these benefits, data teams must migrate their enterprise data warehouses (EDWs) in accordance with time-tested principles for effective data integration. Those principles include alignment with business objectives, balancing standardization with customization, preparation for future requirements, and careful integration with persistent heritage systems. This blog, the second in a series on data integration for the hybrid Azure cloud, defines data migration and applies those principles to EDW migrations.
To recap blog 1 in our series, data integration means ingesting and transforming data, schema, and metadata, in a workflow called a “pipeline” that connects sources and targets. In many cases the sources are operational, and the targets are analytical. You need to manage those pipelines and control their data integration processes for governance purposes. Microsoft’s SQL Server Integration Services (SSIS) and Azure Data Factory (ADF) help data engineers and architects perform data integration tasks based on commands they enter through either a command line or graphical interface. Mid-sized enterprises, and understaffed data teams within larger enterprises, also can use a tool such as TimeXtender to further automate, streamline, and accelerate these tasks.
Data integration includes four components: ingestion, transformation, pipeline management, and control, as shown in this diagram.
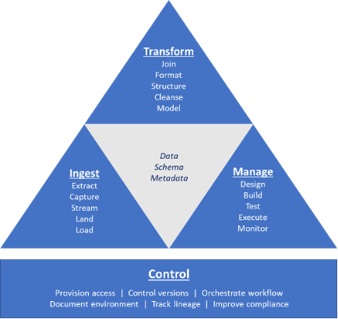
Enterprise data warehouse (EDW) migration—the movement of EDW elements from one place to another—is a primary use case for data integration. In fact, EDW migration goes a step beyond data integration because it moves not just data, schemas, and metadata, but also data models and the pipelines themselves. Here are the primary elements, starting with the most basic and working upward, that you need to consider when you migrate your EDW. As you’ll see, the data itself, even mountains of it, poses less of a challenge than other elements.
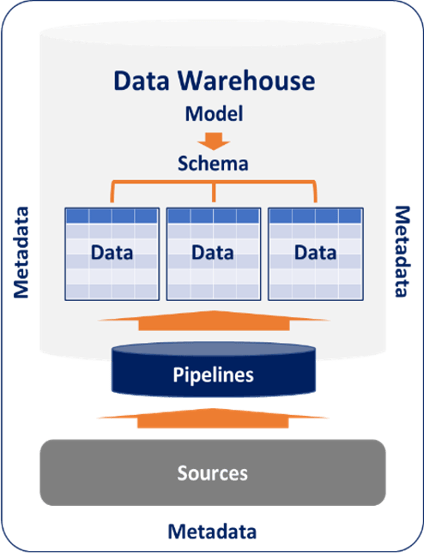
- Data. The EDW assembles data in tables that comprise rows (a.k.a. records) and columns (attributes).
- Model. EDWs depend on models that define the relationships among datasets at an abstract level.
- Schema. The schema implements the data model by defining the specific structures of data, tables, databases, views, and indices.
- Pipeline. The pipeline contains the sequence of instructions for your system to ingest data from sources and transform that data so the EDW can analyze it.
- Metadata. EDWs track additional information, called metadata, that further describes data, models, schema, sources, and pipelines. Metadata also includes information about EDW usage metrics, security settings, and the semantic layer that presents data for business user consumption.
We can picture these elements with the following diagram.
A migration moves some or all of these elements from an old EDW to a new EDW. What you do not move, you must build fresh. Let’s examine how guiding principles we offered in our first blog, in bolded text below, can help data engineers plan and execute an effective cloud EDW migration—specifically an on-premises heritage EDW to Azure Synapse Analytics. Also check out the blog “On the Path to Modernization: Migrating Your Data Warehouse to the Cloud,” by my colleague Dave Wells, to get a comprehensive picture of the EDW migration process.
- Start and finish with business objectives. Let efficiency and compliance guide your migration project. Like other cloud data warehouses, Azure Synapse offers elastic compute and storage that improve scalability and replace capital expenditure with operating expenses. But some analytics queries might still bust budgets on the cloud. Be sure to profile your workload behavior before deciding what data to migrate. You might find that you can support consistent, predictable workloads—and their underlying data—more cost-effectively with well-utilized servers running on premises. Also determine the impact of a cloud migration on your compliance requirements, for example requirements related to the geographic location of customer records. Finally, as described in blog 1, seek out automated pipeline tools that reduce the time and effort of your EDW migration.
- Standardize where you can. The more elements you make interchangeable, the more efficient your migration. If you have reusable models, schema, or pipelines that worked well on the old EDW, migrate them or reverse-engineer them on the new EDW. If instead they contain brittle or custom code, take this opportunity to start fresh by building flexible new elements. Also use commercial tools such as TimeXtender to graphically design, configure, execute, monitor, and store data pipelines from many sources into SQL Server or Azure Synapse. Finally, collect and manage your metadata in a flexible repository, ideally a data catalogue that inventories all your data assets.
- Customize where you must. As stated in our first blog, each business has peculiarities that require a custom approach. Some elements—perhaps models, schema or pipelines—will still require hand scripting. You can accommodate these scenarios by selecting commercial data integration tools that make custom elements a modular part of the migration process. These tools should allow you to import a custom SQL transformation job, for example, then edit that script in a command-line window that pops up within your GUI. Then you save the changes, reinsert the script into your pipeline, activate it, and monitor the results. When necessary, you can decouple that custom script from the pipeline once again and make modular changes that do not affect other components.
- Look around the corner. Your first migration will not be your last. Create a list of future migration scenarios, including sources, targets, and analytics use cases. As you prepare your first migration, try to assemble, build, and store elements—and commercial tools—that can be used for as many of these future scenarios as possible. This process might slow your next migration but minimize technical debt and accelerate each migration thereafter.
- Embrace the old. You might never move all your operations off that mainframe system. However, you can expect to adopt new ways to analyze that operational data. Invest in tools and processes today that can flexibly load and stream data from those heritage systems to current and future analytics targets. Prepare for your latency and throughput requirements to get more stringent in the future. Also be sure to minimize the footprint of data integration technologies such as change data capture. Seek out data integration tools that do not impose software agents or intrusive CDC triggers onto production workloads.
Your data warehouse migration to Azure Synapse offers a great opportunity to improve how you integrate data. You must adhere to business objectives, balance standardization with customization, and balance future and traditional requirements. If you apply these guiding principles during the migration, you can generate longer-lasting benefits from your people, processes, and tools. Our next blog—the third and final in our series—explores how to move mountains even further by integrating data for machine learning use cases.
If you'd like to learn more about data integration in Microsoft environments, please join Kevin Petrie of Eckerson Group and Joseph Treadwell of TimeXtender for a webinar, The Art and Science of Data Integration for Hybrid Azure Environments. This webinar will be held Jun 16, 2021 02:00 PM Eastern Time. Can't make it then? Please sign up so you will receive access to the recording after the event.
Or read the Eckerson Group Deep Dive Report on Hybrid Cloud Data Integration. (no form to fill out!)