









3 min read

Azure Synapse Dedicated SQL Pool (previously Azure SQL Data Warehouse), is a massively parallel processing database similar to other columnar-based, scale-out database technologies such as Snowflake, Amazon Redshift, and Google BigQuery.
To the end-user it’s much like traditional SQL Server, however, behind the scenes it distributes the storage and processing of data across multiple nodes. While this can drastically improve performance for data warehouses larger than a few terabytes, it may not be an ideal solution for smaller implementations. Because the underlying architecture is so drastically different, the syntax and development methodologies also differ from traditional SQL Server.
(One related note, when you use TimeXtender with Azure Synapse Analytics the code is generated for you).
Okay, let’s explore this issue a bit more starting with looking at costs.
1. Compute vs Storage Costs
Azure Synapse Analytics helps users better manage costs by separating computation and storage of their data. Users can pause the service, thereby releasing the compute resources back into Azure. While paused, users are only charged for the storage currently in use (roughly $125 USD/Month/Terabyte). During this time, your data remains intact but unavailable via queries. Resuming the SQL Pool re-allocates compute resources to your account, and your data comes back online and charges resume.
Similar to Azure SQL DB's DTUs, computation in a Synapse SQL Pool is measured by Data Warehouse Units (DWUs). Adjusting DWUs will increase or decrease the number of available compute nodes as well as relative performance and cost of the service.

2. Architecture
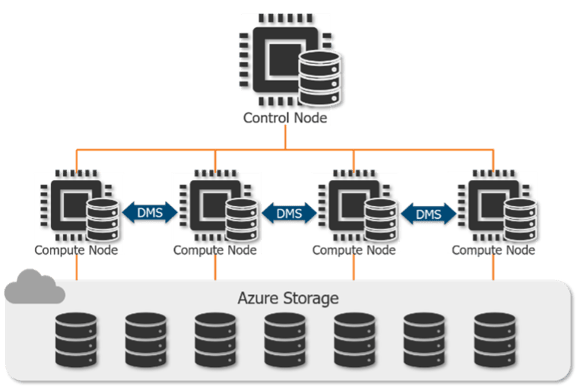
Processing of data in a Synapse SQL Pool is distributed across many nodes of different types.
The control node accepts end-user queries, then optimizes and coordinates these queries to run in parallel across the multiple compute nodes.
While a traditional SQL database is dependent on the computational resources of a single machine, a Synapse SQL Pool can distribute the processing of tables across up to 60 compute nodes depending on the service level. The more DWU's you've assigned, the more compute nodes will be used.
To maintain data integrity while scaling, data is maintained in Azure Storage separate from the control and compute nodes. In addition, to further optimize the processing of large data sets, tables are always spread across 60 distributions (more about this in the next section).
Data Movement Service (DMS) manages the movement of this data across the compute nodes.
3. Table Distribution
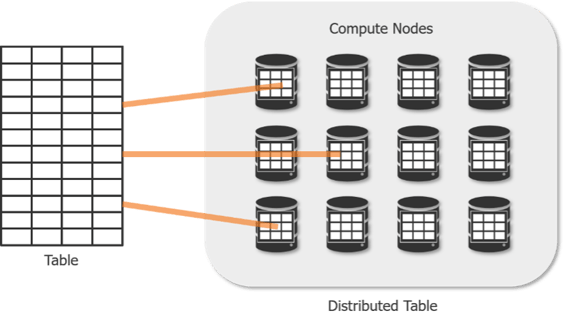
To balance processing across many nodes, tables are split up across 60 distributions. This process is known as “sharding.” The distribution method determines how rows in a table are organized across nodes.
-
Round-robin(default) - Randomly distributes rows evenly across nodes. Not optimized for query performance as there is no logic to how the data is split. Joining to round-robin tables often require shuffling data which takes more time. This is ideal for staging tables.
-
Replicated - This replicates all rows of the table on every node. As you can imagine, load times are not optimal. However, queries on this table are fast because shuffling of data is never necessary. This is ideal for dimension tables smaller than 2GB.
-
Hash - Rows are distributed across nodes using a "distribution column." The SQL Pool uses this column to distribute the data across nodes, keeping all rows with the same value in the same node. This option delivers the highest query performance for joins and aggregations on large tables.

Choosing a Distribution Column
To help choose a distribution column that will result in the best performance, you can follow these guidelines.
- No Updates - Distribution columns cannot be updated
- Even Distribution of Values - For best performance, all distributions should have the same number of rows. Queries can only be as fast as the largest distribution. To achieve this, aim for columns that have:
- Many unique values- more unique, higher chance of evening the distribution.
- Few or No Nulls
- Not a Date Column - If all users are filtering on the same date, only one node will be doing all the processing.
- Join or Group by Column - Selecting a distribution column that is commonly used in a join or group by clause reduces the amount of data movement to process a query.
- If no good option - Create a composite column using multiple join columns.
When should you consider Azure Synapse Analytics?
> 1TB Database - Since tables in Azure Synapse are always spread across 60 distributions, performance gains are not typically realized until your data warehouse is more than 1-5 TB. As a general rule data warehouses of less than 1 TB will perform better on Azure SQL DB than on DW.
> Billion Row Tables - Database size is not the only consideration. Since distribution happens at the table level if all your tables are less than 100 million rows, you may not see a significant performance boost from Azure Synapse.
< 128 Concurrent Queries - Once the SQL Pool has received more than 128 concurrent queries, it will begin to queue them in a first-in-first-out basis. Azure SQL DB and Analysis Services can support much more concurrent queries. To resolve this limitation, it is recommended that you feed data into an Analysis Service Server for larger demand.
Data Warehouse Tuning
How tables are distributed should be based on how users query the data and the approach can drastically effect performance. So the Synapse SQL Pool is not a magic fix to all your query performance problems. Just like a data warehouse running on traditional SQL Server, it requires monitoring and tuning of the distribution keys, indexes, caching, and partitions to ensure best performance.

Further Consideration
By the way, TimeXtender began supporting Azure Synapse as a target database in version 19.11.2. This functionality enables the use of Azure Synapse Analytics as a target Data Warehouse or Staging Database. When also connected to Azure Data Lake via the ODX Server, users can simply drag and drop data from Data Lake to a Synapse SQL Pool with TimeXtender.
Here's a video guide showing how to set up SQL Pool for use with TimeXtender.