







5 min read

A guest blog post from Kevin Petrie, VP of Research at Eckerson Group
As enterprises adopt machine learning, they find it’s a lot easier to make a model than to implement and manage it.
Machine learning (ML) is a subset of artificial intelligence in which an algorithm discovers patterns in data to help predict, classify, and prescribe future outcomes. ML relies on a model, which is essentially an equation that defines the relationship between key data inputs (your “features”) and outcomes (also known as “labels”). ML applies various techniques to create this model, including supervised learning techniques, which study known prior outcomes, and unsupervised learning techniques, which find patterns without knowing outcomes beforehand. Enterprises use machine learning to address many use cases. For example, they detect fraud, recommend customer actions, predict prices, prevent equipment breakdowns, and spot health risks.
While enterprise data teams can devise all kinds of clever ML models, they struggle to implement and manage those models in production. They contend with high data volumes, shifting datasets, and complex operational processes. Enterprises that succeed with ML manage it as part of a holistic lifecycle that spans data and feature engineering, model development, and model operations. This blog describes actions and guiding principles to optimize the ML lifecycle in Azure data warehouse environments, including Azure Synapse and Azure ML.
To start, here are definitions of the three lifecycle stages. For detailed descriptions, also check out parts one and two blogs in my series, “The Machine Learning Lifecycle and MLOps: Building and Operationalizing ML Models.”
-
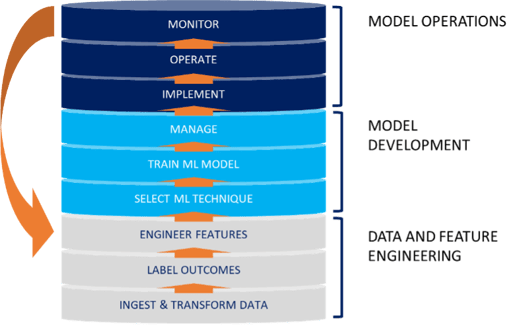
- Data and feature engineering: Ingest and transform your input data (i.e., your historical data), label your outcomes, then “engineer” (i.e., define and store) your features.
- Model development: Select the ML technique you will use (such as linear regression, classification, or “random forests” that make use of decision trees), train your algorithm, then release it as a final model for production use.
- ML operations (MLOps): Put those models to work! Implement, operate, and govern them in production workflows. Monitor their performance and the accuracy of their output. When data drifts and models become less accurate, iterate the process. Take the models out of production to re-engineer your features, change your ML technique, or simply re-train the model on more recent data.
The following diagram illustrates the three stages and nine steps of the ML lifecycle.
Azure Synapse includes a SQL-based data warehouse that provides structured, consistent, and accurate data to ML algorithms. Solutions such as TimeXtender streamline the lifecycle by automatically configuring, executing, and monitoring the necessary tasks that Synapse performs. Together these tools contribute to five key steps in the ML lifecycle: ingesting and transforming data, labeling outcomes, engineering features, training models, and operating those models. This diagram illustrates the five key steps.
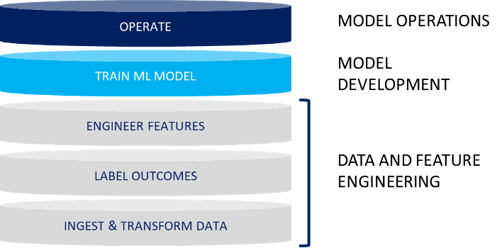
So how do we make this stuff work in an Azure Synapse data warehouse? Let’s explore actions and guiding principles for each step, working chronologically from the bottom up in our diagram.
-
- Ingest and transform your data. Data engineers typically design, configure, and deploy data pipelines that ingest input data into a data warehouse. They merge and format that data into consolidated tables. They also cleanse the data, resolving conflicts, inconsistencies, and redundancies, to ensure accuracy. ML raises the need for accuracy because you never want to automate bad decisions based on bad data. Data scientists must guide data engineers—or even manage the pipelines themselves—to ensure the resulting datasets meet their ML objectives. They must tailor the data sources, formats, column headers, value ranges, and ingestion latency meet the requirements of their use case.
- Label your outcomes. Next data engineers collaborate with business owners to “label” various outcomes in their historical data sets. This means they add tags to data—or simply relabel column headers—to identify historical outcomes, such as fraudulent transactions, factory part failures, or patient pulse rates. Labeling is usually straightforward for structured data because the values make the label obvious. For example, values such as transaction fraud and factory part failures can become “yes/no” labels; “patient pulse rates” might simply be labeled as such. However, data scientists should guide this effort to ensure labels meet their needs. For example, if they plan to use a classification ML technique, they need categorical labels such as “yes/no” or “high/low.” If they use a linear regression technique, they need numerical labels such as patient pulse rates.
Note that labeling applies to supervised ML only. Unsupervised ML, by definition, studies input data without known outcomes, which means the data has no labels.
-
- Engineer your features. The data scientist and data engineer next extract or derive, then share “features”—the key attributes that really drive outcomes—from all that input data. Features become the filtered, clean inputs for an ML algorithm to study, so that it does not drown in data while creating the model. A consolidated, cleansed table in Azure Synapse might have 1,000 columns. By applying some statistical techniques and domain knowledge, they might winnow those 1,000 columns down to 5-7 telling features that explain most of the variance in outcomes. For example, they might find that an online customer’s cumulative purchase amount, date of first purchase, and income level have the biggest influence on whether they will accept an upsell recommendation when they click to check out. Those columns become the features on which you train your algorithm and create a sufficiently accurate ML model without spending too much on cloud compute.
Some enterprises use commercial products called feature stores, which help transform data, define and refine features, then curate and serve them to various ML algorithms. But you might not need a dedicated feature store. Data teams often can handle feature engineering for basic use cases and midsized datasets simply by using the ingestion and transformation capabilities of Azure Synapse and Azure Data Factory.
Once data teams have ingested and transformed their historical input data, labeled the historical outcomes and engineered their features, they are ready to start building the ML model. This model will define the relationship between features and labels, as shown below.

-
- Train your ML model. Once the data scientist selects their ML technique, they can download the right algorithm from open-source libraries such as PyTorch, Scikit-Learn, and TensorFlow, and customize it in the Azure ML model management service. Then they “train” the algorithm on the table of features and historical data they built in Azure Synapse. “Training” in this case means that the data scientist and ML engineer apply the algorithm to combinations of historical features and outcomes (a.k.a. labels) so that it can learn the relationship between them. As it learns, the algorithm generates a score that predicts, classifies, or prescribes outcomes of features. The data scientist compares those predicted outcomes to real historical outcomes, then makes changes to improve accuracy, with the help of the ML engineer and data engineer.
Automated solutions such as TimeXtender provide a graphical interface to make the necessary changes on datasets within Azure Synapse. They can help ingest more training data, and add or remove features (i.e., columns). They also can change the weighting of features within the ML algorithm, using TimeXtender or Azure ML. After each round of changes, the data scientist and ML engineer run the algorithm again on the training data, generate a new score, and check the results. They repeat the process until the scores become sufficiently accurate. This results in a final ML model, ready for production.
-
- Operate your model. Now the fun begins! The data warehouse helps you put that model to work in a few ways. First, you can apply the model to production data within the data warehouse, treating it as custom logic that generates your predictions, classifications, etc. You can apply the same transformation logic to production data as to your training data to ensure it meets the formatting and accuracy requirements of your ML model. You also can monitor model accuracy as data drifts, for example by measuring differences between production and training data. You might identify value changes in a given feature, such as a spike in average patient pulse rates, that indicates other factors are at play—and your model needs retraining.
Enterprises that make the most of their Azure data warehouse, addressing the steps outlined here, will position themselves for success with ML. They can peek above the clouds to see a sky of opportunities.
If you'd like to learn more about data integration in Microsoft environments, please join Kevin Petrie of Eckerson Group and Joseph Treadwell of TimeXtender for a webinar, The Art and Science of Data Integration for Hybrid Azure Environments. This webinar will be held Jun 16, 2021 02:00 PM Eastern Time. Can't make it then? Please sign up so you will receive access to the recording after the event.
Or read the Eckerson Group Deep Dive Report on Hybrid Cloud Data Integration. (no form to fill out!)